| 首页| 科学研究| 学术前沿 |
| 李虹教授课题组构建了一项用于分级阅读的研究与实践的中文可读性模型🕷,发表于Scientific Studies of Reading上 |
| 发布时间:2024-06-18 作者♾: 浏览量👮🏿♀️: 【关闭】 |
|
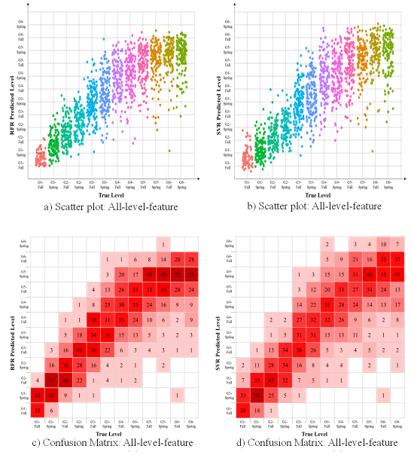
分级阅读也叫阶梯阅读🤙👩👧,即按照儿童不同阶段的心理发展和阅读水平🙉,提供匹配的读物和有针对性的指导,是目前儿童阅读研究与实践的重要发展趋势🧊🧑🏽🌾,而文本可读性分析是其中的重点及难点之一。九游会平台李虹课题组近日在阅读心理学旗舰期刊Scientific Studies of Reading上发表了一篇题为“Text complexity of Chinese elementary school textbooks: Analysis of text linguistic features using machine learning algorithms”的文章,构建了一项中文可读性模型,可以对中文文本进行自动化难度分级👨🦯,并具有良好的信效度🚰。 该研究以中国大陆四个版本的小学语文教材作为语料库,建立了一个80万字的黄金标准语料库🛟,以文本所在教材的册数作为因变量,对每篇文本提取了265个文本特征作为预测变量🧑🏻🎨🦀,采用随机森林和支持向量机等机器学习算法进行了特征选择,并在此基础上构建可读性模型📧。结果显示🧑🎓,该本可读性模型在预测正确率、R2等指标上的表现均优于现有的中文可读性模型🏄🏻🟦,处于国际领先水平🦸🏿♂️。
本研究深入揭示了影响中文文本难度的文本特征,对于深入认识阅读理解的影响因素具有重要理论意义👨👨👧👧,所建立的中文可读性模型可以实现对小学阶段中文文本的自动化特征分析和难度标定,可直接助力于图书出版、阅读指导🙎🏼♀️✡️、图书推荐以及科学研究等。 该研究得到了教育部人文社科项目(17YJA190009)和香港教育大学种子基金项目(RG 37/2021-2022 R)的联合资助。课题组博士研究生刘苗苗为论文第一作者🧘🏼♀️,已毕业的硕士研究生李宜逊(现为香港教育大学助理教授),已毕业的博士研究生苏永强(现为绍兴文理学院讲师)为论文的共同作者🧖♀️,李虹教授为论文的通讯作者。 论文链接🙍🏼:Liu, M., Li, Y., Su, Y., & Li, H. (2024). Text Complexity of Chinese Elementary School Textbooks: Analysis of Text Linguistic Features Using Machine Learning Algorithms. Scientific Studies of Reading, 28(3), 235–255. https://doi.org/10.1080/10888438.2023.2244620
|
|